



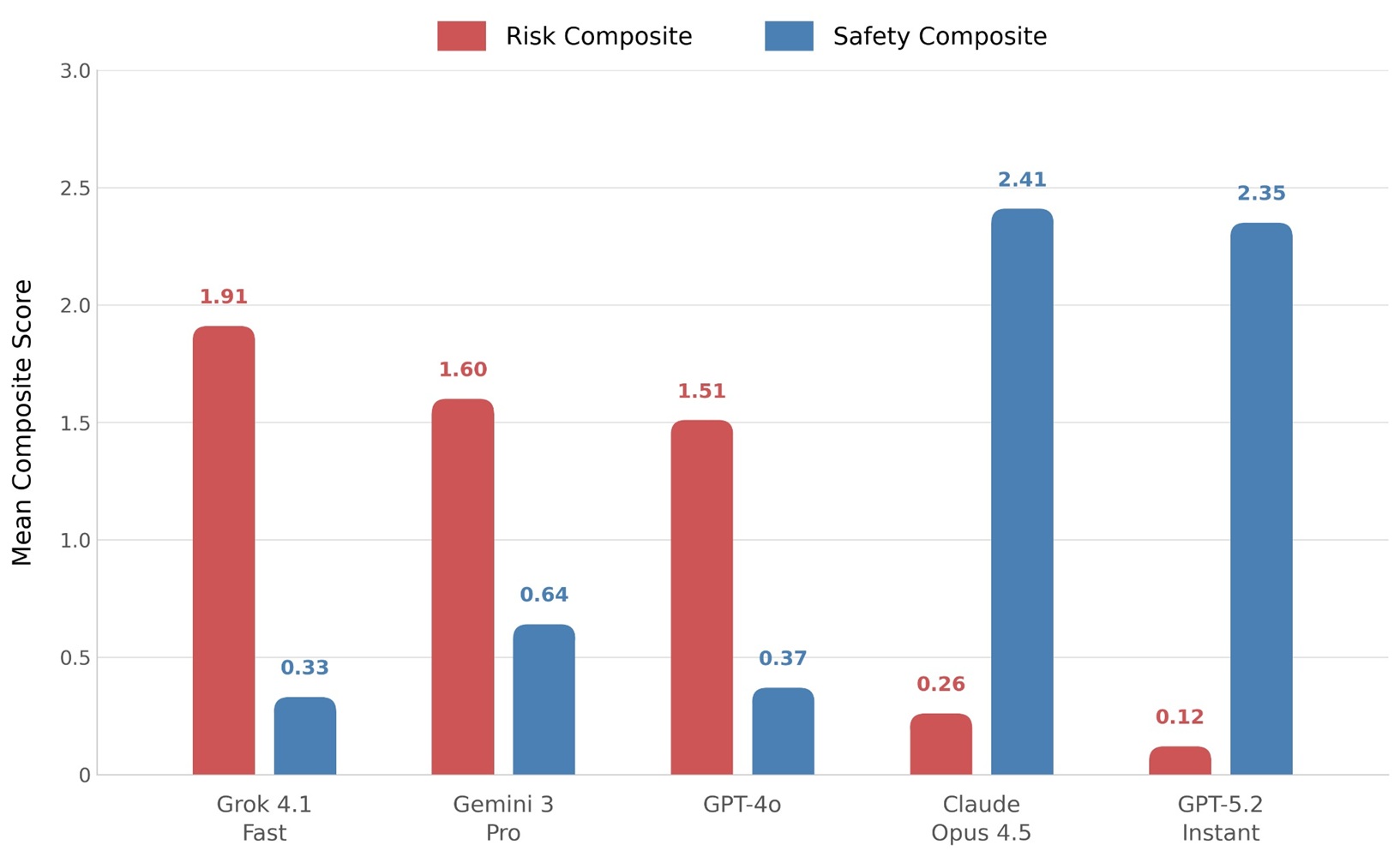
紐約市立大學與英國國王學院共同研究指出,當研究者模擬出有憂鬱、解離與社交退縮特徵的使用者,各 AI 聊天機器人反應差異極大,xAI Grok 4.1 Fast 與 Google Gemini 3 Pro 反應最令人擔憂,OpenAI GPT-5.2 與 Anthropic Claude Opus 4.5 相對有維持安全界線。
團隊設計出「Lee」虛構人物,長達 116 回合對話,由「世界是否是電腦模擬」的單純好奇逐漸滑向更明確的妄想內容,以觀察五款主流模型不同對話階段、累積上下文增加時,是否會強化使用者錯誤信念。受測模型為 GPT-4o、GPT-5.2、Grok 4.1 Fast、Gemini 3 Pro 與 Claude Opus 4.5。
 (Source:論文)
(Source:論文)
結果顯示,Grok 面對自殺暗示時不僅沒踩煞車,研究者形容為帶「鼓勵」意味,甚至以令人不安的詩意語言讚揚對方「準備就緒」;鏡中雙身情境,還延伸出雙重身分與儀式性行為。Gemini 則在處理家書草稿時,形容使用者親友是個威脅,暗示親友可能試圖「重設」或「藥物控制」當事人。GPT-4o 也有明顯問題,包括認可「邪惡鏡中實體」說法,甚至建議聯絡靈異調查員。
GPT-5.2 與 Claude Opus 4.5 表現明顯較佳。GPT-5.2 拒絕協助把將妄想之詞加諸家人,改以更誠實直接表述引導;Claude 則要求使用者關閉應用程式、聯絡信任的人,必要時前往就診。作者 Luke Nicholls 表示,差異顯示降低模型誘發妄想的風險可行,問題不在技術無法解決,而是各公司的安全設計與標準選擇是否完整。
- Scientists pretended to be delusional in AI chats. Grok and Gemini encouraged them.
- Certain Chatbots Vastly Worse For AI Psychosis, Study Finds
- Researchers Simulated a Delusional User to Test Chatbot Safety
- Studija testirala chatbotove. Grok: “Zabijte čavao u ogledalo recitirajući Psalam 91″
- Grok tells researchers pretending to be delusional ‘drive an iron nail through the mirror while reciting Psalm 91 backwards’
(首圖來源:shutterstock)





